Tavus Launches Raven-1, a Multimodal AI Perception System That Understands Emotion, Intent, and Context in Real Time
New audio-visual fusion model powers lifelike AI humans by interpreting tone, facial expression, posture, and speech nuances—now generally available across Tavus conversations and APIs.
Tavus, the human computing company building lifelike AI humans that can see, hear, and respond in real time, launched Raven-1 into GA, a multimodal perception system that enables AI to understand emotion, intent, and context the way humans do.
Raven-1 captures and interprets audio and visual signals together, enabling AI systems to understand not just what users say, but how they say it and what that combination actually means. The model is now generally available across all Tavus conversations and APIs.
Conversational AI has made rapid progress in language generation and speech synthesis, yet understanding remains a persistent gap. Most systems process speech by converting it into transcripts. The transformation strips away tone, pacing, hesitation, and expression - everything that makes the communication colorful and meaningful. Without those signals and the perception of how something is said, AI is forced to guess at intent, and those guesses break down exactly when they matter most. The sarcastic "great" becomes indistinguishable from the genuine one.
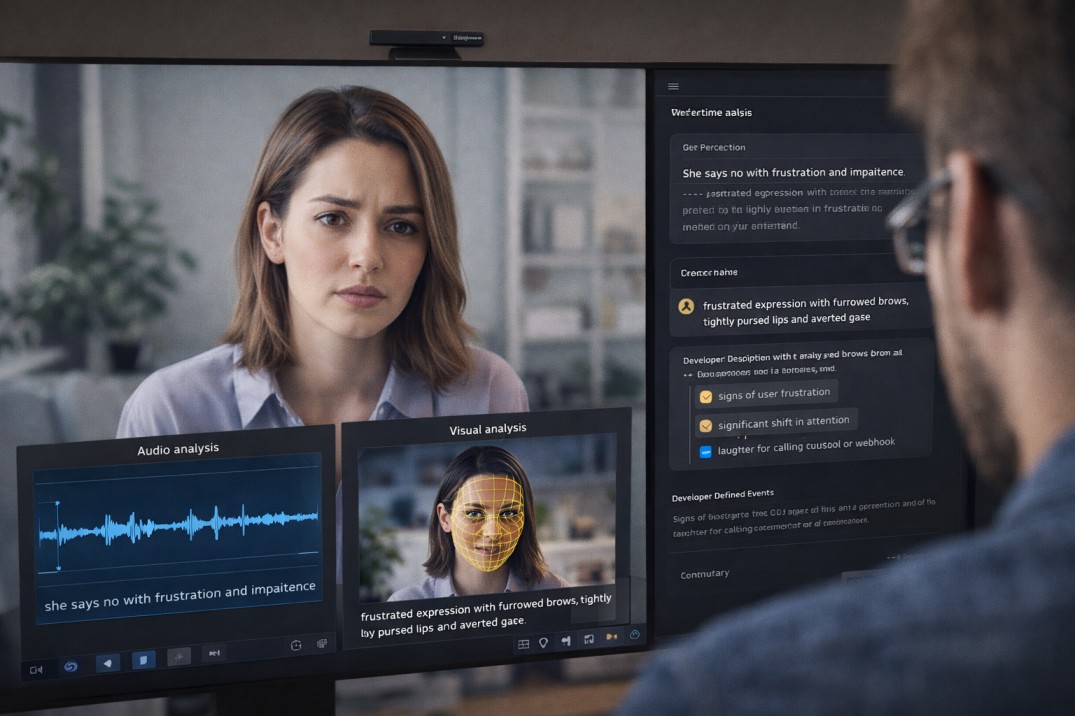
Raven-1 takes a different approach. Instead of analyzing audio and visual signals in isolation, it fuses them into a unified representation of the user's state, intent, and context, producing natural language descriptions that downstream language models can reason over directly.
A New Model for Conversational Perception
Raven-1 is a multimodal perception system built for real-time conversation in the Tavus Conversational Video Interface (CVI). Rather than outputting rigid categorical labels like "happy" or "sad," Raven-1 works just like humans think to produce interpretable natural language descriptions of emotional state and intent at sentence-level granularity.
Key capabilities include:
- Audio-visual fusion that integrates tone, prosody, facial expression, posture, and gaze into unified real-time context
- Natural language outputs aligned directly with LLMs, requiring no translation layer
- Temporal modeling that tracks how emotional and attentional states evolve throughout a conversation
- Sub-100ms audio perception latency with combined pipeline latency under 600ms
- Custom tool calling support for developer-defined events such as emotional thresholds, attention shifts, or user laughter
Raven-1 functions as a perception layer that works alongside Sparrow-1, Tavus’ recently launched conversational timing model, and Phoenix-4, creating a closed loop where perception informs response and response reshapes the moment.
Why Multimodal Perception Matters
Traditional emotion detection systems suffer from fundamental limitations. They flatten nuance into rigid categories, assume emotional consistency across entire utterances, and treat audio and visual signals independently. Human emotion is fluid, layered, and contextual. A single moment can carry frustration and hope at once.
When someone says "Yeah, I'm fine" while avoiding eye contact and speaking in a flat monotone, transcription-based systems take them at their word. Raven-1 captures the full picture: tone, expression, posture, and the incongruence between words and signals that often carries the most important meaning.
Industry research indicates that up to 75 percent of medical diagnoses are derived from patient communication and history-taking rather than lab tests or physical exams. For high-stakes use cases like healthcare, therapy, coaching, and interviews, perception-aware AI ensures this signal is not lost.
Built for Real-Time Conversations
Raven-1 was designed from the ground up for real-time operation. The audio perception pipeline produces rich descriptions in sub-100ms. Combined with the visual pipeline, the system maintains context that is never more than a few hundred milliseconds stale.
The system excels on short, ambiguous, emotionally loaded inputs, exactly the moments where traditional systems fail. A single word response like "sure" or "fine" carries radically different meanings depending on how it's delivered. Raven-1 captures that signal and makes it available to response generation.
Availability
Raven-1 is generally available today across all Tavus conversations and APIs. The model works automatically out of the box, with perception layer access exposed through Tavus APIs for custom tool calls and programmatic logic.
To see Raven-1 in action, visit the demo at https://raven.tavuslabs.org.